Методы Оптимизации, Теормин
Материал из eSyr's wiki.
м (→Теорема о границах решений задач ЛП с целыми коэффициентами) |
(→Индивидуальная и массовая задачи, кодировка задачи, алгоритм решения массовой задачи, временная сложность алгоритма.) |
||
| (114 промежуточных версий не показаны.) | |||
| Строка 1: | Строка 1: | ||
| + | {{Курс Методы оптимизации}} | ||
| + | |||
== Введение в теорию сложности == | == Введение в теорию сложности == | ||
=== Индивидуальная и массовая задачи, кодировка задачи, алгоритм решения массовой задачи, временная сложность алгоритма. === | === Индивидуальная и массовая задачи, кодировка задачи, алгоритм решения массовой задачи, временная сложность алгоритма. === | ||
| + | ''Методичка, стр. 4-8'' | ||
'''Массовая задача <math>\Pi</math>''': | '''Массовая задача <math>\Pi</math>''': | ||
* список свободных параметров; | * список свободных параметров; | ||
* формулировка свойств, которым должно удовлетворять решение задачи. | * формулировка свойств, которым должно удовлетворять решение задачи. | ||
| + | |||
<math>\Pi</math> есть множество индивидуальных задач <math>I \in \Pi</math>. '''Индивидуальная задача''' получается, если всем параметрам присвоить конкретные значения. | <math>\Pi</math> есть множество индивидуальных задач <math>I \in \Pi</math>. '''Индивидуальная задача''' получается, если всем параметрам присвоить конкретные значения. | ||
| - | Пусть <math>\Sigma</math> | + | |
| + | Пусть <math>\Sigma</math> — конечный алфавит, а <math>\Sigma^*</math> — множество слов в этом алфавите. Отображение e: <math>\Pi \rightarrow \Sigma^*</math> называется кодировкой задачи <math>\Pi</math>. | ||
| + | |||
'''Алгоритм <math>A</math> решает массовую задачу''' <math>\Pi</math>, если для любой индивидуальной задачи <math>I \in \Pi</math> : | '''Алгоритм <math>A</math> решает массовую задачу''' <math>\Pi</math>, если для любой индивидуальной задачи <math>I \in \Pi</math> : | ||
| Строка 14: | Строка 20: | ||
* <math>A</math> дает решение <math>I</math> | * <math>A</math> дает решение <math>I</math> | ||
| - | '''Кодировка задачи P''' | + | |
| + | '''Кодировка задачи P''' — такое отображение <math>e: P \rightarrow \Sigma^* </math>, обладающее следующими свойствами: | ||
* Возможность однозначно декодировать, то есть у двух различных ИЗ не может быть одинаковых кодировок. | * Возможность однозначно декодировать, то есть у двух различных ИЗ не может быть одинаковых кодировок. | ||
| - | * <math>e, e^{-1}</math> | + | * <math>e, e^{-1}</math> — полиномиально вычислимы |
* Кодировка не избыточна, то есть для любой другой кодировки <math>e_1</math>, удовлетворяющей 1 и 2 условиям справедливо: | * Кодировка не избыточна, то есть для любой другой кодировки <math>e_1</math>, удовлетворяющей 1 и 2 условиям справедливо: | ||
| - | <math>\exists p(.): \forall I \in | + | <math>\exists p(.): \forall I \in \Pi ~~ |e(I)| < p(|e_{1}(I)|)</math> |
| - | '''Язык массовой задачи''' -- это множество правильных слов, то есть слов, соответствующих ИЗ, имеющим положительный ответ(подразумевается задача распознавания): <math>L(\Pi, e) = e(Y(\Pi)) = \{s \in \Sigma^*| s = e(I), I \in Y(\Pi)\}</math> | ||
| - | '''Язык | + | '''Язык массовой задачи''' — это множество правильных слов, то есть слов, соответствующих ИЗ, имеющим положительный ответ(подразумевается задача распознавания): <math>L(\Pi, e) = e(Y(\Pi)) = \{s \in \Sigma^*| s = e(I), I \in Y(\Pi)\}</math> |
| - | + | '''Язык алгоритма''' — множество слов, принимаемых <math>A</math>, то есть таких, на которых алгоритм останавливается в состоянии <math>q_Y</math>, что соответсвует "да": <math>L(A) = \{\sigma \in \Sigma^* | A(\sigma) = q_Y\}</math> | |
| - | <math> | + | Алгоритм <math>A</math> '''решает''' массовую задачу <math>\Pi</math>, с кодировкой <math>e</math>, если <math>L(e, \Pi) = L(A)</math> и <math>\forall s \in \Sigma^*</math> А останавливается |
| - | '''Временная сложность''' <math>T_{A}(n) = | + | |
| + | '''Число шагов''' алгоритма <math>A</math> для входа <math>s \in \Sigma^*</math> — это <math>t_{A}(s)</math>. | ||
| + | |||
| + | '''Временная сложность''' <math>T_{A}(n) = max_{s \in \Sigma^*, |s| < n} \{t_{A}(s)\} </math>. | ||
=== Задачи распознавания свойств. Классы P и NP.=== | === Задачи распознавания свойств. Классы P и NP.=== | ||
| + | ''Методичка, стр. 8-11'' | ||
'''Задача распознавания свойств''' -- массовая задача, предполагающая ответ "да" или "нет", в качестве своего решения. | '''Задача распознавания свойств''' -- массовая задача, предполагающая ответ "да" или "нет", в качестве своего решения. | ||
| Строка 36: | Строка 46: | ||
* <math>Y(\Pi)</math> -- множество всех индивидуальных задач, ответом на которые является "да". | * <math>Y(\Pi)</math> -- множество всех индивидуальных задач, ответом на которые является "да". | ||
| - | '''Класс полиномиально разрешимых задач (P)''' -- это такие задачи, | + | '''Класс полиномиально разрешимых задач (P)''' -- это такие задачи, временная сложность алгоритма решения которых ограниченна полиномом: |
* <math>\exists A</math> такой, что <math>A</math> решает массовую задачу <math>\Pi</math> с кодировкой <math>e</math> | * <math>\exists A</math> такой, что <math>A</math> решает массовую задачу <math>\Pi</math> с кодировкой <math>e</math> | ||
* <math>\exists p(\cdot)</math> -- полином такой, что <math>T_A(n) < p(n)~~,~\forall n \in Z_{+}</math> | * <math>\exists p(\cdot)</math> -- полином такой, что <math>T_A(n) < p(n)~~,~\forall n \in Z_{+}</math> | ||
| Строка 45: | Строка 55: | ||
* задачи, для которых длина записи выхода превышает любой наперед заданный полином от длины входа | * задачи, для которых длина записи выхода превышает любой наперед заданный полином от длины входа | ||
** найти все маршруты в задаче коммивояжёра | ** найти все маршруты в задаче коммивояжёра | ||
| + | * ∀А, решающего П с кодировкой e, ∀p(·) ∃I ∈ П: <math>t_A(e(I)) > p(|e(I)|)</math> | ||
| - | '''Класс | + | |
| + | '''Класс недетерминированно полиномиальных задач (NP)''' -- это такие задачи, для которых существует алгоритм решения на недерменированной машине Тьюринга: | ||
* <math>\exists \hat{A}</math> для НДМТ такой, что <math>\hat{A}</math> решает массовую задачу <math>\Pi</math> с кодировкой <math>e</math> | * <math>\exists \hat{A}</math> для НДМТ такой, что <math>\hat{A}</math> решает массовую задачу <math>\Pi</math> с кодировкой <math>e</math> | ||
* <math>\exists p(\cdot)</math> -- полином такой, что <math>\hat{T}_{\hat{A}}(n) < p(n)~~,~\forall n \in Z_{+}</math> | * <math>\exists p(\cdot)</math> -- полином такой, что <math>\hat{T}_{\hat{A}}(n) < p(n)~~,~\forall n \in Z_{+}</math> | ||
=== Теорема об экспоненциальной временной оценке для задач из класса NP. === | === Теорема об экспоненциальной временной оценке для задач из класса NP. === | ||
| + | ''Методичка, стр. 11'' | ||
Для любой <math>\Pi \in NP</math> существует ДМТ <math>A</math>, решающая ее с не более чем экспоненциальной временной сложностью: <math>T_A(n) \leqslant 2^{p(n)} </math>. | Для любой <math>\Pi \in NP</math> существует ДМТ <math>A</math>, решающая ее с не более чем экспоненциальной временной сложностью: <math>T_A(n) \leqslant 2^{p(n)} </math>. | ||
=== Класс co-NP. Пример задачи, допускающей хорошую характеризацию. Доказательство утверждения о взаимоотношении классов NPC и co-NP. === | === Класс co-NP. Пример задачи, допускающей хорошую характеризацию. Доказательство утверждения о взаимоотношении классов NPC и co-NP. === | ||
| + | ''Методичка, стр. 12-14'' | ||
'''Дополнительная задача <math>\overline\Pi</math>''' к массовой задаче <math>\Pi</math> -- задача, получаемая из <math>\Pi</math> путем введения альтернативного вопроса. То есть если в <math>\Pi</math> спрашиваем "верно ли <math>x</math>", то в <math>\overline\Pi</math> спрашиваем "верно ли, что <math>\neg x</math>" | '''Дополнительная задача <math>\overline\Pi</math>''' к массовой задаче <math>\Pi</math> -- задача, получаемая из <math>\Pi</math> путем введения альтернативного вопроса. То есть если в <math>\Pi</math> спрашиваем "верно ли <math>x</math>", то в <math>\overline\Pi</math> спрашиваем "верно ли, что <math>\neg x</math>" | ||
| Строка 64: | Строка 78: | ||
Класс <math>\text{co-NP}</math> -- <math>\{\overline{\Pi} | \Pi \in NP\}</math>. | Класс <math>\text{co-NP}</math> -- <math>\{\overline{\Pi} | \Pi \in NP\}</math>. | ||
| - | * <math>\text{co-NP} = NP</math> пока не удалось ни доказать, ни опровергнуть. | + | * <math>\text{co-NP} = NP</math> пока не удалось ни доказать, ни опровергнуть, но это вряд ли верно. |
* <math>P \in NP \cap \text{co-NP}</math> | * <math>P \in NP \cap \text{co-NP}</math> | ||
| - | Массовая задача <math>\Pi</math> '''допускает хорошую | + | Массовая задача <math>\Pi</math> '''допускает хорошую характеризацию''', если <math>\Pi \in \text{NP} \cap \text{co-NP}</math> |
* пример такой задачи -- это задача определения простоты числа. | * пример такой задачи -- это задача определения простоты числа. | ||
* <math>P \subseteq \text{NP} \cap \text{co-NP}</math> | * <math>P \subseteq \text{NP} \cap \text{co-NP}</math> | ||
| Строка 80: | Строка 94: | ||
=== Критерий NP-полноты. Д-во NP-полноты задачи ЦЛН === | === Критерий NP-полноты. Д-во NP-полноты задачи ЦЛН === | ||
| + | ''Методичка, стр. 15'' | ||
| - | + | ''' Критерий NP-полноты. ''' Массовая задача <math>\Pi</math> '''NP-полна''' тогда и только тогда, когда она принадлежит классу '''NP''' и к ней полиномиально сводится какая-либо '''NP-полная''' задача. | |
| + | === Д-во NP-полноты задачи 3-выполнимость. NP-трудные задачи === | ||
| + | ''Методичка, стр. 17-18'' | ||
| + | <u>Класс ''' NP-трудных ''' задач содержит: </u> | ||
| + | # задачи распознавания свойств <math>\Pi</math>, для которых | ||
| + | #* не доказано, что <math>\Pi \in \textrm{NP}</math> | ||
| + | #* <math>\exists \Pi' \in \textrm{NPC} : \Pi' \propto \Pi</math> | ||
| + | # задачи оптимизации, для которых соответствующие задачи распознавания свойств <math>\Pi \in \mathrm{NPC}</math> | ||
| + | # любые задачи, к которым сводятся по Тьюрингу хотя бы одна ''' NP-полная ''' задача | ||
=== Взаимоотношение классов P, NP и NPC, NP и co-NP. Класс PSPACE === | === Взаимоотношение классов P, NP и NPC, NP и co-NP. Класс PSPACE === | ||
| - | '' | + | Легко показать, что <math>P \subseteq \text{NP} \cap \text{co-NP}</math>. Рабочая ''гипотеза'', что <math>P = \text{NP} \cap \text{co-NP}</math>. |
| - | + | Если для некоторой NP-полной задачи <math>\Pi</math> дополнительная к ней задача <math>\overline{\Pi} \in \text{NP}</math>, то <math>\text{NP} = \text{co-NP}</math> | |
Класс '''PSPACE''' массовых задач -- класс алгоритмов, требующих не более, чем полиномиальной памяти. | Класс '''PSPACE''' массовых задач -- класс алгоритмов, требующих не более, чем полиномиальной памяти. | ||
| - | ''Гипотеза.'' <math>\text{P} \subset \text{PSPACE}</math>. При этом NP-полные, NP-трудные, NP-эквивалентные задачи <math> \subset \text{PSPACE} \setminus \text{P}</math> | + | ''Гипотеза.'' <math>\text{P} \subset \text{PSPACE}</math> (то есть, не факт, что вложение строгое, но скорее всего так). При этом NP-полные, NP-трудные, NP-эквивалентные задачи <math> \subset \text{PSPACE} \setminus \text{P}</math> |
=== Псевдополиномиальные алгоритмы. Пример для задачи о рюкзаке === | === Псевдополиномиальные алгоритмы. Пример для задачи о рюкзаке === | ||
| Строка 100: | Строка 123: | ||
Пусть <math>M(I)</math> -- некоторая функция, задающая значение числового параметра индивидуальной задачи <math>I</math>. Если таких параметров несколько, в качестве <math>M(I)</math> можно взять или максимальное, или среднее значение, а если задача вовсе не имеет числовых параметров (например, раскраска графа, шахматы и т.п.), то <math>M(I) = 0</math>. Алгоритм называется псевдополиномиальным, если он имеет оценку трудоемкости <math>T_{max}(I) = O(p(|I|, M(I)))</math>, где <math>p(\cdot, \cdot)</math> -- некоторый полином от двух переменных. | Пусть <math>M(I)</math> -- некоторая функция, задающая значение числового параметра индивидуальной задачи <math>I</math>. Если таких параметров несколько, в качестве <math>M(I)</math> можно взять или максимальное, или среднее значение, а если задача вовсе не имеет числовых параметров (например, раскраска графа, шахматы и т.п.), то <math>M(I) = 0</math>. Алгоритм называется псевдополиномиальным, если он имеет оценку трудоемкости <math>T_{max}(I) = O(p(|I|, M(I)))</math>, где <math>p(\cdot, \cdot)</math> -- некоторый полином от двух переменных. | ||
| + | |||
| + | [http://en.wikipedia.org/wiki/Pseudo-polynomial_time en-wiki] | ||
=== Сильная NP-полнота. Теорема о связи сильной NP-полноты задачи с существованием псевдополиномиального алгоритма ее решения === | === Сильная NP-полнота. Теорема о связи сильной NP-полноты задачи с существованием псевдополиномиального алгоритма ее решения === | ||
| Строка 105: | Строка 130: | ||
'''Полиномиальное сужение''' массовой задачи <math>\Pi</math> -- множество таких индивидуальных задач <math>I</math>, числовые параметры которых не превосходят полинома от длины входа: <math>\Pi_{p(\cdot)} = \{ I \in \Pi | M(I) \leqslant p(|I|) \}</math> | '''Полиномиальное сужение''' массовой задачи <math>\Pi</math> -- множество таких индивидуальных задач <math>I</math>, числовые параметры которых не превосходят полинома от длины входа: <math>\Pi_{p(\cdot)} = \{ I \in \Pi | M(I) \leqslant p(|I|) \}</math> | ||
| - | Массовая задача <math>\Pi</math> называется '''сильно NP-полной''', если её полиномиальное сужение является NP-полным. | + | Массовая задача <math>\Pi</math> называется '''сильно NP-полной''', если её полиномиальное сужение является NP-полным. Примеры: |
* задача выполнимости, задача 3-выполнимости -- совпадают со своими полиномиальными сужениями | * задача выполнимости, задача 3-выполнимости -- совпадают со своими полиномиальными сужениями | ||
| - | * задача булевых линейных неравенств | + | * задача булевых линейных неравенств -- ВЫП сводится к её полиномиальноу сужению, где числовые параметры (правая часть неравенств) линейны. |
| - | * задача о целочисленном решении системы линейных уравнений | + | * задача о целочисленном решении системы линейных уравнений -- , т.к. БЛН сводится к ней |
| - | * задача | + | * задача коммивояжёра (TSL) -- совпадает со своим сужением |
| - | === Определение | + | Задача о рюкзаке -- слабо-NPC. |
| + | |||
| + | Теорема. Если NP не совпадает с P, то ни для какой сильно-NPC задачи не существует псевдополиномиального решения. | ||
| + | |||
| + | === Определение ε-приближенного алгоритма и полностью полиномиальной приближенной схемы (ПППС). Связь между существованием ПППС и псевдополиномиальностью === | ||
| + | '' Методичка, стр. 22-24 '' | ||
| + | |||
| + | ''' Задача дискретной оптимизации ''' -- решение каждой индивидуальной задачи <math>I \in \Pi</math> является произвольная реализация оптимума <math>\mathrm{Opt}_\Pi(I) = \max_{z \in S_\Pi(I)} f_\Pi(I, z)</math>, где | ||
| + | * <math>S_\Pi(I)</math> -- область допустимых значений дискретной переменной <math>z</math> | ||
| + | * <math>f_\Pi</math> -- целевая функция задачи оптимизации | ||
| + | * <math>\max</math> вообще говоря вполне может быть заменён на <math>\min</math> | ||
| + | |||
| + | Алгоритм <math>A</math> называется '''приближённым алгоритмом''' решения массовой задачи <math>\Pi</math>, если для любой задачи <math>I \in \Pi</math> он находит точку <math>z_A(I) \in S_\Pi(I)</math>, лежащую в области допустимых значений, принимаемую за приближённое решение. | ||
| + | |||
| + | ''Утверждение''. Если <math>\mathrm{P} \neq \mathrm{NP}</math>, то ни для какой константы <math>C > 0</math> не существует полиномиального приближённого алгоритма решения задачи о рюкзаке с оценкой <math>| \mathrm{Opt}(I) - A(I) | \leqslant C</math>. | ||
| + | |||
| + | Приближённый алгоритм <math>A</math> решения массовой задачи <math>\Pi</math> называется ''' <math>\varepsilon</math>-приближённым алгоритмом ''' решения задачи, если <math>\forall I \in \Pi : ~ \left| \frac{\mathrm{Opt}_\Pi(I) - A(I)}{\mathrm{Opt}_\Pi(I)} \right| \leqslant \varepsilon</math>. | ||
=== Теорема об отсутствии ПППС для задач оптимизации, соответствующих сильно NP-полным задачам распознавания === | === Теорема об отсутствии ПППС для задач оптимизации, соответствующих сильно NP-полным задачам распознавания === | ||
| + | ''Методичка, стр. 24'' | ||
| + | |||
| + | '''Теорема''' Если для <math>\Pi</math> оптимизации | ||
| + | * соответствующая ей задача распознавания свойств является сильно NP-полной | ||
| + | * существует полином <math>\exists p'(\cdot) : \mathrm{Opt}_\Pi(I) < p'(M(I)) ~~ \forall I \in \Pi</math> | ||
| + | то при условии, что <math>\mathrm{P} \neq \mathrm{NP}</math> для <math>\Pi</math> не существует ПППС | ||
== Основы линейного программирования == | == Основы линейного программирования == | ||
| Строка 123: | Строка 170: | ||
| - | '''Утверждение (принцип граничных решений)'''. Если озЛП имеет решение, то найдется такая подматрица <math>A_I</math> матрицы <math>A</math>, что любое решение системы уравнений <math>A_I x = b_I</math> реализует максимум <math>c | + | '''Утверждение (принцип граничных решений)'''. Если озЛП имеет решение, то найдется такая подматрица <math>A_I</math> матрицы <math>A</math>, что любое решение системы уравнений <math>A_I x = b_I</math> реализует максимум <math>\langle c,x \rangle</math>. |
'''Алгебраическая сложность''' -- количество арифметических операций. | '''Алгебраическая сложность''' -- количество арифметических операций. | ||
| Строка 130: | Строка 177: | ||
Вопрос о существовании алгебраически-полиномиального алгоритма для ЛП остается открытым. | Вопрос о существовании алгебраически-полиномиального алгоритма для ЛП остается открытым. | ||
| + | |||
| + | === Геометрическое описание симплекс-метода === | ||
| + | (Копипаста из [[http://ru.wikipedia.org/wiki/%D0%A1%D0%B8%D0%BC%D0%BF%D0%BB%D0%B5%D0%BA%D1%81-%D0%BC%D0%B5%D1%82%D0%BE%D0%B4 ru.wiki]], там-же есть хорошая иллюстрация.)<br> | ||
| + | Симплекс-метод -- метод решения озЛП. | ||
| + | |||
| + | Каждое из линейных неравенств в <math>Ax \leqslant b</math> ограничивает полупространство в соответствующем линейном пространстве. В результате все неравенства ограничивают некоторый многогранник (возможно, бесконечный), называемый также полиэдральным конусом. | ||
| + | Уравнение <math>W(x) = c</math>, где <math>W(x)</math> — максимизируемый (или минимизируемый) линейный функционал, порождает гиперплоскость <math>L(c)</math>. Зависимость от <math>c</math> порождает семейство параллельных гиперплоскостей. Тогда экстремальная задача приобретает следующую формулировку — требуется найти такое наибольшее <math>c</math>, что гиперплоскость <math>L(c)</math> пересекает многогранник хотя бы в одной точке. Заметим, что пересечение оптимальной гиперплоскости и многогранника будет содержать хотя бы одну вершину. Принцип симплекс-метода состоит в том, что выбирается одна из вершин многогранника, после чего начинается движение по его ребрам от вершины к вершине в сторону увеличения значения функционала. Когда переход по ребру из текущей вершины в другую вершину с более высоким значением функционала невозможен, считается, что оптимальное значение c найдено. | ||
=== Теорема о границах решений задач ЛП с целыми коэффициентами === | === Теорема о границах решений задач ЛП с целыми коэффициентами === | ||
| + | ''Методичка, стр. 28-29'' | ||
| - | <math>\Delta(D) = \max | \det(D_1) | </math>, где <math>D_1</math> | + | <math>\Delta(D) = \max | \det(D_1) | </math>, где <math>D_1</math> — квадратная подматрица <math>D</math>. |
| - | Если задача | + | '''Теорема (о границах решений).''' Если задача озЛП <math>d^{*} = \max\langle c, x\rangle, x \in \mathbb{R}^{n}, Ax \leqslant b</math> размерности (n, m) с целыми коэффициентами разрешима, то у нее существует рациональное решение <math>x^{*}</math> в шаре: <math>\| x^{*}\| \leqslant \sqrt{n} \Delta([A|b])</math> и <math>d^{*} = \frac{t}{s}~,~~ t,s \in Z,~~|s| \leqslant \Delta(A)</math> |
=== Теорема о мере несовместности систем линейных неравенств с целыми коэффициентами === | === Теорема о мере несовместности систем линейных неравенств с целыми коэффициентами === | ||
| + | ''Методичка, стр. 29'' | ||
| - | + | <math>x^{\varepsilon}</math> -- '''<math>\varepsilon</math>-приближенное решение системы ЛН''', если | |
| + | * в строчной записи: <math>\langle a_i , x^{\varepsilon} \rangle \leqslant b_i + \varepsilon~,~~ \forall i \in [1,m]</math> | ||
| + | * в матричной записи: <math>Ax^\varepsilon \leqslant b + \varepsilon e</math>, где <math>e</math> -- вектор-столбец из единиц | ||
| - | '''Теорема'''. Если система линейных неравенств имеет <math>\ | + | '''Теорема'''. Если система линейных неравенств имеет <math>\varepsilon_1</math> приближенное решение (<math>\varepsilon_1 = \frac{1}{(n+2)\Delta(A)}</math>), то эта система разрешима, то есть имеет точное решение. |
=== Описание метода эллипсоидов === | === Описание метода эллипсоидов === | ||
| + | * ''Методичка, стр. (30-32) 32-33'' | ||
| + | * [http://ru.wikipedia.org/wiki/%D0%9C%D0%B5%D1%82%D0%BE%D0%B4_%D1%8D%D0%BB%D0%BB%D0%B8%D0%BF%D1%81%D0%BE%D0%B8%D0%B4%D0%BE%D0%B2 вики:Метод эллипсоидов] | ||
| - | '''Лемма1.'''Если система | + | Решает задачу линейного программирования за полиномиальное число шагов. |
| + | |||
| + | Суть алгоритма в том, чтобы окружить данный многогранник эллипсоидом, а затем постепенно сжимать этот эллипсоид; оказывается, на каждом этапе объем эллипсоида уменьшается в константное число раз. | ||
| + | |||
| + | '''Лемма1.''' Если система <math>Ax \leqslant b</math> совместна, то в шаре <math>E_0 = \| x \| \leqslant \sqrt{n} \Delta([A|b])</math> найдется ее решение. | ||
Таким образом получаем, что если система совместна, то эта лемма позволяет локализовать хотбы бы 1 из ее решений | Таким образом получаем, что если система совместна, то эта лемма позволяет локализовать хотбы бы 1 из ее решений | ||
| + | |||
| + | Введем функцию невязки в точке x -- <math>t(x) = \max_i((Ax)_i - b_i)</math>. Точка <math>x^{0}=\overline{0}</math> -- это центр шара <math>E_0</math>. Если <math> t(x^{0}) \leqslant 0</math>, то <math>x^{0}</math> -- решение. Если это не так, то возьмем s: <math>t(x) = \langle a_{s},x^{0}\rangle - b_s</math>, значит <math>x^{0}</math> не удовлетворяет s-ому неравенству системы. Всякий вектор <math>x</math>, удовлетворяющий неравенству s, должен лежать в полупространстве <math>\leqslant \langle a_s, x^{0}\rangle</math>. Пересечение этого полупространства с нашей сферой дают полуэлипсоид. Вокруг получившегося полуэлипсоида описываем новую сферу и повторяем алгоритм заново. | ||
| + | |||
| + | === Теория двойственности ЛП === | ||
| + | * ''Методичка, стр. 35-36'' | ||
| + | * http://www.mathelp.spb.ru/book1/lprog5.htm | ||
| + | |||
| + | Каждой задаче линейного программирования можно определенным образом сопоставить некоторую другую задачу (линейного программирования), называемую двойственной или сопряженной по отношению к исходной или прямой задаче. | ||
| + | |||
| + | '''Двойственной задачей''' к задаче линейного программирования <math>Ax \leqslant b</math> на максимум <math>\langle c, x\rangle</math> (в форме ОЗЛП можно записать: <math>\max_{x \in \mathbb{R}^n:~Ax \leqslant b} \langle c, x \rangle</math>) называется задача линейного программирования на минимум: <math>\min_{\lambda \in \mathbb{R}^n:~\lambda A = c,~\lambda \geqslant \overline{0}} \langle \lambda, b \rangle</math> | ||
| + | |||
| + | ''Утверждение'' Двойственная задача к двойственной задаче совпадает с прямой задачей линейного программирования. | ||
| + | |||
| + | '''Теорема (двойственности ЛП).''' Задача ЛП разрешима тогда и только тогда, когда разрешима двойственная к ней. При этом в случае разрешимости оптимальные значения целевых функций совпадают: <math>\max_{x \in \mathbb{R}^n:~Ax \leqslant b} \langle c, x \rangle ~ = ~\min_{\lambda \in \mathbb{R}^n:~\lambda A = c,~\lambda \geqslant \overline{0}} \langle \lambda, b \rangle</math> | ||
| + | |||
| + | === Сведение озЛП к однородной системе уравнений с огрничением x>0 === | ||
| + | ''Методичка, стр 36-37'' | ||
| + | |||
| + | ''Утверждение.'' Задача ЛП оптимизации эквивалентна решению системы линейных неравенств. | ||
| + | |||
| + | ''Утверждение.'' Задача ЛП оптимизации эквивалентна решению системы линейных уравнений в неотрицательных переменных. | ||
| + | |||
| + | ''Утверждение.'' Задача ЛП эквивалентна поиску неотрицательного ненулевого решения однородной системы линейных уравнений. | ||
| + | |||
| + | === Идея метода Кармаркара === | ||
| + | * ''Методичка, стр 37-38'' | ||
| + | * http://logic.pdmi.ras.ru/~yura/modern/02seminar.pdf | ||
| + | |||
| + | '''Метод Кармаркара.''' | ||
| + | # На основании предыдущего утверждения (см. вопрос о сведении озЛП к однородной системе), есть возможность свести задачу ЛП <math>\max_{x \in \mathbb{R}^n:~Ax \leqslant b} \langle c, x \rangle</math> к поиску решения СЛАУ <math>\hat{P}y = \hat{q},~ y \geqslant \overline{0}</math>, которая, в свою очередь, сводится к однородной СЛАУ: <math>Py = \overline{0},~ y \geqslant \overline{0}</math> | ||
| + | # Введем '''функцию Кармаркара''': <math>k(x) = \frac{\left[ (\langle p_1, x \rangle)^2 + \dots + (\langle p_K, x \rangle)^2\right]^{N/2}}{x_1 \cdot x_2 \cdot \dots \cdot x_N}</math>, где | ||
| + | #* <math>N</math> -- число столбцов в <math>P</math> | ||
| + | #* <math>K</math> -- число строк в <math>P</math> | ||
| + | #* <math>p_i, ~ i \in [1,K]</math> -- строки матрицы <math>P</math> | ||
| + | # применяя теорему о мере несовместимости и алгоритм округления можно показать, что для решения достаточно найти такой <math>\hat{x}</math>, для которого <math>k(\hat{x}) \leqslant \frac{1}{3 \left(\Delta(\hat{P})\right)^N}</math> | ||
| + | # при этом можно так же показать полиномиальный алгоритм поиска данного приближения, который в курсе не рассматривается. | ||
| + | |||
| + | === Следствия систем линейных неравенств. Афинная лемма Фаркаша (без доказательства) === | ||
| + | * ''Методичка, стр. 34-35'' | ||
| + | * http://imcs.dvgu.ru/lib/nurmi/finmath/node41.html | ||
| + | |||
| + | Система линейных неравенств <math>Ax \leqslant b</math> называется '''разрешимой''', если <math>\exists x : ~~ Ax \leqslant b</math> | ||
| + | |||
| + | Линейное неравенство <math>\langle c, x\rangle \leqslant d</math> является '''следствием разрешимой системы ЛН''' <math>Ax \leqslant b</math>, если для всех <math>x</math>, для которых выполняется сама система, выполняется и следствие: <math>\forall x : Ax \leqslant b ~~ \Rightarrow ~~ \langle c, x\rangle \leqslant d</math> | ||
| + | |||
| + | '''Афинная лемма Фаракша.''' | ||
| + | Линейное неравентсво <math>\langle c, x\rangle \leqslant d</math> является следствием разрешимой в вещественный переменных ЛН <math>Ax \leqslant b</math>, тогда и только тогда, когда существуют <math>\lambda _i \in \mathbb{R}</math>: | ||
| + | * <math>c = \sum_{i \in M} \lambda_i a_i</math> | ||
| + | * <math>d \geqslant \sum_{i \in M}\lambda_ib_i</math> | ||
| + | * <math>\lambda_i \geqslant 0 ~~ \forall i \in M</math> | ||
| + | |||
| + | === Лемма Фаркаша о неразрешимости === | ||
| + | ''Методичка, стр. 35'' | ||
| + | |||
| + | '''Лемма'''. | ||
| + | Система линейных неравенств <math>Ax \leqslant b</math> неразрешима тогда и только тогда, когда разрешима система: | ||
| + | |||
| + | * <math>\sum_{i \in M}\lambda_i a_i = \overline{0}</math> (нулевой вектор) | ||
| + | * <math>\sum_{i \in M}\lambda_i b_i \leqslant -1</math> | ||
| + | * <math>\lambda_i \geqslant 0 ~~ \forall i \in M</math> | ||
| + | |||
| + | == Элементы математического программирования == | ||
| + | |||
| + | === Классификация задач математического программирования. Преимущества выпуклого случая === | ||
| + | ''Методичка. стр 39-41'' | ||
| + | |||
| + | ''' Задача математического программирования (ЗМП) ''' -- по заданной <math>f(x)</math> найти <math>\arg \min_{x \in X} f(x)</math>, то есть: | ||
| + | * найти <math>x^* \in X : ~~ \forall x \in X ~ \Rightarrow ~ f(x^*) \leqslant f(x)</math> -- решение | ||
| + | * <math>f^* = f(x^*)</math> -- (оптимальное) значение целевой функции <math>f(x)</math> | ||
| + | * где <math>X</math> -- допустимое множество (множество ограничений) | ||
| + | |||
| + | Классификация проводится по ''типу допустимого множества'' <math>X</math>: | ||
| + | * ''дискретные (комбинаторные)'' -- множество <math>X</math> конечно или счётно | ||
| + | * ''целочисленные'' -- <math>X \equiv \mathbb{Z}^n</math> | ||
| + | * ''булевы'' -- <math>X \equiv \mathbb{B}^n</math> | ||
| + | * ''непрерывные'' -- <math>X \equiv \mathbb{R}^n</math> | ||
| + | * ''бесконечномерные'' | ||
| + | * ''функциональные'' | ||
| + | |||
| + | Задачи оптимизации бывают: | ||
| + | * ''условные'' -- <math>X \subset \mathbb{R}^n</math> | ||
| + | * ''безусловные'' -- <math>X \equiv \mathbb{R}^n</math> | ||
| + | |||
| + | Классификация по ''свойствам целевой функции'': выпуклость, гладкость и т.п. | ||
| + | |||
| + | Классификация по результату: | ||
| + | * локальная оптимизация | ||
| + | * глобальная оптимизация | ||
| + | |||
| + | '''Выпуклое множество''' ([http://ru.wikipedia.org/wiki/%D0%92%D1%8B%D0%BF%D1%83%D0%BA%D0%BB%D0%BE%D0%B5_%D0%BC%D0%BD%D0%BE%D0%B6%D0%B5%D1%81%D1%82%D0%B2%D0%BE вики]) -- такое множество, которое содержит вместе с любыми двумя своими точками еще и отрезок, их соединяющий. | ||
| + | |||
| + | Функция <math>f</math> называется '''выпуклой''', если её надграфик (множество точек над графиком: <math>\{(x,y):~ y \geqslant f(x) ~ \forall x \in X\}</math>) является выпуклым множеством. | ||
| + | |||
| + | ''Утверждение.'' Любая точка локального минимума выпуклой функции является точкой её глобального минимума. | ||
| + | |||
| + | <u>Преимущества выпуклых задач:</u> | ||
| + | * применим метод эллипсоидов, причем сложность - полиномиальна | ||
| + | * для острых задач (целевая функция убывает в окрестности минимума не медленнее некоторой линейной функции) можно получить точное решение | ||
| + | |||
| + | === Формула градиентного метода в задаче безусловной минимизации === | ||
| + | ''Методичка. стр 41-42'' | ||
| + | |||
| + | Основная идея: | ||
| + | * берем некоторое начальное значение | ||
| + | * итеративно вычисляем [http://ru.wikipedia.org/wiki/%D0%93%D1%80%D0%B0%D0%B4%D0%B8%D0%B5%D0%BD%D1%82 градиент] целевой функции | ||
| + | * двигаемся в обратном направлении | ||
| + | * и так постепенно приходим к (локальному) минимуму функции | ||
| + | |||
| + | '''Формула градиентного метода''' -- <math>x^{t+1} = x^t - \alpha_t \mathrm{grad} f(x^t)</math>, где <math>\alpha_t</math> -- шаговый множитель: | ||
| + | * пассивный способ: <math>\{\alpha_t\}</math> выбирается заранее | ||
| + | * адаптивный способ: <math>\{\alpha_t\}</math> выбирается в зависимости от реализующейся <math>x_t</math> | ||
| + | ** метод скорейшего спуска -- <math>\alpha_t \in \arg \min_{\alpha > 0} f(x^t - \alpha \mathrm{grad} f(x^t))</math> | ||
| + | ** метод дробления (деления пополам) -- если <math>f(x^{t+1}) > f(x^t)</math>, то возвращаемся к шагу <math>t</math> с новым значением <math>\alpha_t = \alpha_t / 2</math> | ||
| + | |||
| + | === Идея метода Ньютона === | ||
| + | ''Методичка, стр. 43'' | ||
| + | |||
| + | '''Метод ньютона''' -- это фактически градиентный спуск с адаптивыным коэффициентом, который берется, как 2 производная целевой функции. | ||
| + | |||
| + | Реально можно вывести формулу Ньютона из [http://ru.wikipedia.org/wiki/%D0%A0%D1%8F%D0%B4_%D0%A2%D0%B5%D0%B9%D0%BB%D0%BE%D1%80%D0%B0 разложения по Тейлору] до 2 производной в окрестности точки минимума. | ||
| + | |||
| + | === Формула метода Ньютона в задаче безусловной минимизации === | ||
| + | ''Методичка. стр 43'' | ||
| + | |||
| + | ''' Формула Ньютона ''' -- <math>x^{t+1} = x^t - \frac{1}{f''(x^t)} \mathrm{grad}f(x^t)</math>, при этом начальное приближение должно находиться достаточно близко к искомой точке минимума. | ||
| + | |||
| + | Метод ньютона имеет <u>квадратичную скорость сходимости</u>: <math>\| x^{t+1} - x^* \| \leqslant \frac{1}{Q} (Q \| x^1 - x^* \|)^2</math>, где <math>Q</math> - некоторая константа | ||
| + | |||
| + | <u>Ограничения:</u> | ||
| + | * невырожденность матрицы 2 производных ([http://ru.wikipedia.org/wiki/%D0%93%D0%B5%D1%81%D1%81%D0%B8%D0%B0%D0%BD_%D1%84%D1%83%D0%BD%D0%BA%D1%86%D0%B8%D0%B8 гессиана]) | ||
| + | * близость начального приближения к точке минимума (<math>\| x^1 - x^* \| < 1/Q</math>) | ||
| + | |||
| + | === Идея метода штрафов === | ||
| + | ''Методичка. стр 44'' | ||
| + | |||
| + | Смысл метода в том, чтобы свести задачу условной оптимизации к задаче безусловной оптимизации, то есть избавится от ограничения на область, в которой ищем минимум. | ||
| + | |||
| + | Для этого вводится так называемая функция штрафа, которая равна нулю в той области, в которой мы "условно оптимизируем" целевую функцию, а в остальных точках добавляет к значению целевой функции некоторое значение (собственно, штраф). | ||
| + | |||
| + | ''Пример.'' Пусть область задаётся следующим образом: <math>X = \{x | g(x) \leqslant 0 \}</math>, где <math>g(x)</math> -- некоторая функция. Тогда рассмотрим задачу безусловной минимизации целевой функции <math>f(x)</math> со штрафом: <math>\min_{x \in \mathbb{R}^n} \{ f(x) + C g(x)^p\}</math>, где <math>C</math> -- некоторая константа [??], а <math>p \geqslant 1</math> -- параметр штрафа | ||
| + | |||
| + | == Способы решения переборных задач == | ||
| + | === Методы глобальной минимизации === | ||
| + | ''Методичка. стр. 52 (52-55)'' | ||
| + | |||
| + | |||
| + | |||
| + | === Метод ветвей и границ для глобальной минимизации Липшицевых функций === | ||
| + | ''Методичка. стр. 54'' | ||
| + | |||
| + | === Метод ветвей и границ для ЦЛП. Различные стратегии метода === | ||
| + | ''Методичка. стр. 57'' | ||
| + | |||
| + | === Идея метода ветвей и границ. Пример для задачи БЛП === | ||
| + | ''Методичка. стр. 59'' | ||
| + | |||
| + | === Теорема оптимальности для разложимых функций === | ||
| + | ''Методичка. стр 60'' | ||
| + | |||
| + | '''Опр.''' Функция f называется '''разделяемой''' на <math>f_1</math> и <math>f_2</math>, если она представима в виде <math>f(x, y) = f_1(x, f_2(y))</math>. | ||
| + | |||
| + | '''Опр.''' Функция f называется '''разложимой''' на <math>f_1</math> и <math>f_2</math>, если: | ||
| + | * она разделяема на <math>f_1</math> и <math>f_2</math> | ||
| + | * <math>f_1</math> монотонно не убывает по последнему аргументу | ||
| + | |||
| + | '''Теорема оптимальности для разложимых функций''': <math> \min_{x,y}(f(x,y)) = \min_x(f_1(x, \min_y(f_2(y)))) </math>. | ||
| + | |||
| + | Указанная теорема используется для уменьшения размерности оптимизационных задач и в методе ДП. | ||
| + | |||
| + | === Применение метода динамического программирования для понижения размерности разложимой оптимизационной задачи === | ||
| + | '' Методичка. стр. 62 '' | ||
| + | |||
| + | === Метод динамического программирования для БЛП с неотрицательными коэффициентами === | ||
| + | '' Методичка. стр. 63-64 '' | ||
| + | |||
| + | == Неотсортировано == | ||
| + | # Полиномиальный алгоритм округления <math>\epsilon_{1}</math>-приближенного решения системы линейных неравенств | ||
| + | # Понятие о временной сложности алгоритмов | ||
| + | # Понятие о недетерминированно-полиномиальных задачах | ||
| + | # Оценка сложности метода эллипсоидов <math>\epsilon_{2}</math>-приближенного решения озЛП | ||
| + | |||
| + | {{Курс Методы оптимизации}} | ||
Текущая версия
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15
Календарь
| пт | пт | пт | пт | пт | |
Февраль
| 08 | 15 | 22 | 29 | |
Март
| 06 | 13 | 20 | 27 | |
Апрель
| 04 | 11 | 18 | 25 | |
Май
| 02 | 16 | 23 |
Материалы
Упражнения
||
Задачи | Определения | Утверждения | Теоремы
||
Теормин | Обозначения
[править] Введение в теорию сложности
[править] Индивидуальная и массовая задачи, кодировка задачи, алгоритм решения массовой задачи, временная сложность алгоритма.
Методичка, стр. 4-8
Массовая задача Π:
- список свободных параметров;
- формулировка свойств, которым должно удовлетворять решение задачи.
Π есть множество индивидуальных задач 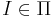 . Индивидуальная задача получается, если всем параметрам присвоить конкретные значения.
. Индивидуальная задача получается, если всем параметрам присвоить конкретные значения.
Пусть Σ — конечный алфавит, а Σ * — множество слов в этом алфавите. Отображение e: 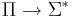 называется кодировкой задачи Π.
называется кодировкой задачи Π.
Алгоритм A решает массовую задачу Π, если для любой индивидуальной задачи :
- A применим к I, то есть останавливается за конечное число шагов
- A дает решение I
Кодировка задачи P — такое отображение 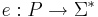 , обладающее следующими свойствами:
, обладающее следующими свойствами:
- Возможность однозначно декодировать, то есть у двух различных ИЗ не может быть одинаковых кодировок.
- e,e − 1 — полиномиально вычислимы
- Кодировка не избыточна, то есть для любой другой кодировки e1, удовлетворяющей 1 и 2 условиям справедливо:
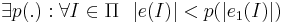
Язык массовой задачи — это множество правильных слов, то есть слов, соответствующих ИЗ, имеющим положительный ответ(подразумевается задача распознавания): 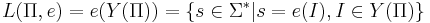
Язык алгоритма — множество слов, принимаемых A, то есть таких, на которых алгоритм останавливается в состоянии qY, что соответсвует "да": 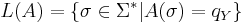
Алгоритм A решает массовую задачу Π, с кодировкой e, если L(e,Π) = L(A) и 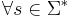 А останавливается
А останавливается
Число шагов алгоритма A для входа 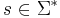 — это tA(s).
— это tA(s).
Временная сложность 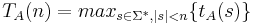 .
.
[править] Задачи распознавания свойств. Классы P и NP.
Методичка, стр. 8-11
Задача распознавания свойств -- массовая задача, предполагающая ответ "да" или "нет", в качестве своего решения.
- D(Π) -- множество всех возможных значений параметров массовой задачи.
- Y(Π) -- множество всех индивидуальных задач, ответом на которые является "да".
Класс полиномиально разрешимых задач (P) -- это такие задачи, временная сложность алгоритма решения которых ограниченна полиномом:
-
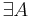 такой, что A решает массовую задачу Π с кодировкой e
такой, что A решает массовую задачу Π с кодировкой e
-
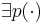 -- полином такой, что
-- полином такой, что 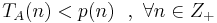
Примеры неполиномиальных задач:
- алгоритмически неразрешимые задачи:
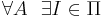 такая, что A не применим к I, например,
такая, что A не применим к I, например, 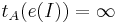
- 10-я проблема Гильберта: по данному многочлену g с целыми коэффициентами выяснить, имеет ли уравнение g = 0 целочисленное решение
- задачи, для которых длина записи выхода превышает любой наперед заданный полином от длины входа
- найти все маршруты в задаче коммивояжёра
- ∀А, решающего П с кодировкой e, ∀p(·) ∃I ∈ П: tA(e(I)) > p( | e(I) | )
Класс недетерминированно полиномиальных задач (NP) -- это такие задачи, для которых существует алгоритм решения на недерменированной машине Тьюринга:
-
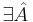 для НДМТ такой, что
для НДМТ такой, что 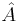 решает массовую задачу Π с кодировкой e
решает массовую задачу Π с кодировкой e
- -- полином такой, что
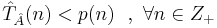
[править] Теорема об экспоненциальной временной оценке для задач из класса NP.
Методичка, стр. 11
Для любой 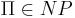 существует ДМТ A, решающая ее с не более чем экспоненциальной временной сложностью:
существует ДМТ A, решающая ее с не более чем экспоненциальной временной сложностью: 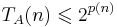 .
.
[править] Класс co-NP. Пример задачи, допускающей хорошую характеризацию. Доказательство утверждения о взаимоотношении классов NPC и co-NP.
Методичка, стр. 12-14
Дополнительная задача 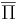 к массовой задаче Π -- задача, получаемая из Π путем введения альтернативного вопроса. То есть если в Π спрашиваем "верно ли x", то в спрашиваем "верно ли, что
к массовой задаче Π -- задача, получаемая из Π путем введения альтернативного вопроса. То есть если в Π спрашиваем "верно ли x", то в спрашиваем "верно ли, что 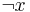 "
"
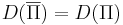
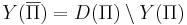
Класс co-P -- 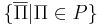
- co-P = P.
Класс co-NP -- 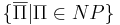 .
.
- co-NP = NP пока не удалось ни доказать, ни опровергнуть, но это вряд ли верно.
-
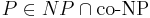
Массовая задача Π допускает хорошую характеризацию, если 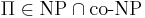
- пример такой задачи -- это задача определения простоты числа.
-
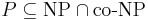
Массовая задача Π' с кодировкой e' полиномиально сводится к задаче Π с кодировкой e, если любая индивидуальная задача 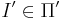 может быть сведена за полиномиальное от её длины время к некоторой задаче с сохранением ответа.
может быть сведена за полиномиальное от её длины время к некоторой задаче с сохранением ответа.
Массовая задача Π называется NP-полной (универсальной), если
- принадлежит классу NP:
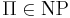
- любая задача из NP полиномиально сводится к Π:
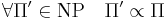
Класс NPC (NP-complete) -- множество всех NP-полных задач.
[править] Критерий NP-полноты. Д-во NP-полноты задачи ЦЛН
Методичка, стр. 15
Критерий NP-полноты. Массовая задача Π NP-полна тогда и только тогда, когда она принадлежит классу NP и к ней полиномиально сводится какая-либо NP-полная задача.
[править] Д-во NP-полноты задачи 3-выполнимость. NP-трудные задачи
Методичка, стр. 17-18
Класс NP-трудных задач содержит:
- задачи распознавания свойств Π, для которых
- не доказано, что
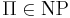
-
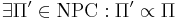
- не доказано, что
- задачи оптимизации, для которых соответствующие задачи распознавания свойств
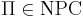
- любые задачи, к которым сводятся по Тьюрингу хотя бы одна NP-полная задача
[править] Взаимоотношение классов P, NP и NPC, NP и co-NP. Класс PSPACE
Легко показать, что . Рабочая гипотеза, что  .
.
Если для некоторой NP-полной задачи Π дополнительная к ней задача 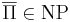 , то NP = co-NP
, то NP = co-NP
Класс PSPACE массовых задач -- класс алгоритмов, требующих не более, чем полиномиальной памяти.
Гипотеза. 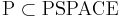 (то есть, не факт, что вложение строгое, но скорее всего так). При этом NP-полные, NP-трудные, NP-эквивалентные задачи
(то есть, не факт, что вложение строгое, но скорее всего так). При этом NP-полные, NP-трудные, NP-эквивалентные задачи 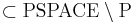
[править] Псевдополиномиальные алгоритмы. Пример для задачи о рюкзаке
Псевдополиномиальный алгоритм - полиномиальный алгоритм, проявляющий экспоненциальный характер только при очень больших значениях числовых параметров.
Пусть M(I) -- некоторая функция, задающая значение числового параметра индивидуальной задачи I. Если таких параметров несколько, в качестве M(I) можно взять или максимальное, или среднее значение, а если задача вовсе не имеет числовых параметров (например, раскраска графа, шахматы и т.п.), то M(I) = 0. Алгоритм называется псевдополиномиальным, если он имеет оценку трудоемкости Tmax(I) = O(p( | I | ,M(I))), где 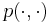 -- некоторый полином от двух переменных.
-- некоторый полином от двух переменных.
[править] Сильная NP-полнота. Теорема о связи сильной NP-полноты задачи с существованием псевдополиномиального алгоритма ее решения
Полиномиальное сужение массовой задачи Π -- множество таких индивидуальных задач I, числовые параметры которых не превосходят полинома от длины входа: 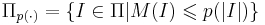
Массовая задача Π называется сильно NP-полной, если её полиномиальное сужение является NP-полным. Примеры:
- задача выполнимости, задача 3-выполнимости -- совпадают со своими полиномиальными сужениями
- задача булевых линейных неравенств -- ВЫП сводится к её полиномиальноу сужению, где числовые параметры (правая часть неравенств) линейны.
- задача о целочисленном решении системы линейных уравнений -- , т.к. БЛН сводится к ней
- задача коммивояжёра (TSL) -- совпадает со своим сужением
Задача о рюкзаке -- слабо-NPC.
Теорема. Если NP не совпадает с P, то ни для какой сильно-NPC задачи не существует псевдополиномиального решения.
[править] Определение ε-приближенного алгоритма и полностью полиномиальной приближенной схемы (ПППС). Связь между существованием ПППС и псевдополиномиальностью
Методичка, стр. 22-24
Задача дискретной оптимизации -- решение каждой индивидуальной задачи является произвольная реализация оптимума 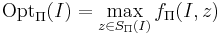 , где
, где
- SΠ(I) -- область допустимых значений дискретной переменной z
- fΠ -- целевая функция задачи оптимизации
- max вообще говоря вполне может быть заменён на min
Алгоритм A называется приближённым алгоритмом решения массовой задачи Π, если для любой задачи он находит точку 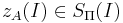 , лежащую в области допустимых значений, принимаемую за приближённое решение.
, лежащую в области допустимых значений, принимаемую за приближённое решение.
Утверждение. Если 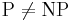 , то ни для какой константы C > 0 не существует полиномиального приближённого алгоритма решения задачи о рюкзаке с оценкой
, то ни для какой константы C > 0 не существует полиномиального приближённого алгоритма решения задачи о рюкзаке с оценкой 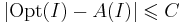 .
.
Приближённый алгоритм A решения массовой задачи Π называется 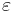 -приближённым алгоритмом решения задачи, если
-приближённым алгоритмом решения задачи, если 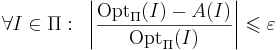 .
.
[править] Теорема об отсутствии ПППС для задач оптимизации, соответствующих сильно NP-полным задачам распознавания
Методичка, стр. 24
Теорема Если для Π оптимизации
- соответствующая ей задача распознавания свойств является сильно NP-полной
- существует полином
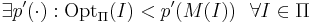
то при условии, что для Π не существует ПППС
[править] Основы линейного программирования
[править] Определение озЛП. Принцип граничных решений. Алгебраическая и битовая сложность ЛП. Результаты о сложности для задач, близких к ЛП
ЛП (линейное программирование) -- теория, приложения и методы решения системы линейных неравенств с конечным числом неизвестных : 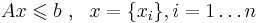 , существует ли
, существует ли  , удовлетворяющий данной системе линейных неравентсв
, удовлетворяющий данной системе линейных неравентсв
озЛП (основная задача линейного программирования) : найти такой вектор -- решение задачи линейного программирования 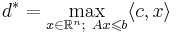 , максимизирующее линейную функцию
, максимизирующее линейную функцию 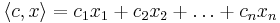
Утверждение (принцип граничных решений). Если озЛП имеет решение, то найдется такая подматрица AI матрицы A, что любое решение системы уравнений AIx = bI реализует максимум 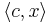 .
.
Алгебраическая сложность -- количество арифметических операций.
Битовая сложность -- количество операций с битами. Битовая сложность задач ЛП, ЛН полиномиальна.
Вопрос о существовании алгебраически-полиномиального алгоритма для ЛП остается открытым.
[править] Геометрическое описание симплекс-метода
(Копипаста из [ru.wiki], там-же есть хорошая иллюстрация.)
Симплекс-метод -- метод решения озЛП.
Каждое из линейных неравенств в 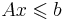 ограничивает полупространство в соответствующем линейном пространстве. В результате все неравенства ограничивают некоторый многогранник (возможно, бесконечный), называемый также полиэдральным конусом.
Уравнение W(x) = c, где W(x) — максимизируемый (или минимизируемый) линейный функционал, порождает гиперплоскость L(c). Зависимость от c порождает семейство параллельных гиперплоскостей. Тогда экстремальная задача приобретает следующую формулировку — требуется найти такое наибольшее c, что гиперплоскость L(c) пересекает многогранник хотя бы в одной точке. Заметим, что пересечение оптимальной гиперплоскости и многогранника будет содержать хотя бы одну вершину. Принцип симплекс-метода состоит в том, что выбирается одна из вершин многогранника, после чего начинается движение по его ребрам от вершины к вершине в сторону увеличения значения функционала. Когда переход по ребру из текущей вершины в другую вершину с более высоким значением функционала невозможен, считается, что оптимальное значение c найдено.
ограничивает полупространство в соответствующем линейном пространстве. В результате все неравенства ограничивают некоторый многогранник (возможно, бесконечный), называемый также полиэдральным конусом.
Уравнение W(x) = c, где W(x) — максимизируемый (или минимизируемый) линейный функционал, порождает гиперплоскость L(c). Зависимость от c порождает семейство параллельных гиперплоскостей. Тогда экстремальная задача приобретает следующую формулировку — требуется найти такое наибольшее c, что гиперплоскость L(c) пересекает многогранник хотя бы в одной точке. Заметим, что пересечение оптимальной гиперплоскости и многогранника будет содержать хотя бы одну вершину. Принцип симплекс-метода состоит в том, что выбирается одна из вершин многогранника, после чего начинается движение по его ребрам от вершины к вершине в сторону увеличения значения функционала. Когда переход по ребру из текущей вершины в другую вершину с более высоким значением функционала невозможен, считается, что оптимальное значение c найдено.
[править] Теорема о границах решений задач ЛП с целыми коэффициентами
Методичка, стр. 28-29
Δ(D) = max | det(D1) | , где D1 — квадратная подматрица D.
Теорема (о границах решений). Если задача озЛП 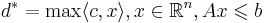 размерности (n, m) с целыми коэффициентами разрешима, то у нее существует рациональное решение x * в шаре:
размерности (n, m) с целыми коэффициентами разрешима, то у нее существует рациональное решение x * в шаре: ![\| x^{*}\| \leqslant \sqrt{n} \Delta([A|b])](/w/images/math/e/0/c/e0cfc825906139f9a1ad88f1ff4bac17.png) и
и 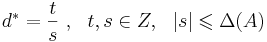
[править] Теорема о мере несовместности систем линейных неравенств с целыми коэффициентами
Методичка, стр. 29
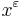 -- -приближенное решение системы ЛН, если
-- -приближенное решение системы ЛН, если
- в строчной записи:
![\langle a_i , x^{\varepsilon} \rangle \leqslant b_i + \varepsilon~,~~ \forall i \in [1,m]](/w/images/math/4/a/c/4ac9484c50325adc33b8a9fd58ccfa44.png)
- в матричной записи:
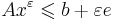 , где e -- вектор-столбец из единиц
, где e -- вектор-столбец из единиц
Теорема. Если система линейных неравенств имеет 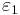 приближенное решение (
приближенное решение (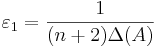 ), то эта система разрешима, то есть имеет точное решение.
), то эта система разрешима, то есть имеет точное решение.
[править] Описание метода эллипсоидов
- Методичка, стр. (30-32) 32-33
- вики:Метод эллипсоидов
Решает задачу линейного программирования за полиномиальное число шагов.
Суть алгоритма в том, чтобы окружить данный многогранник эллипсоидом, а затем постепенно сжимать этот эллипсоид; оказывается, на каждом этапе объем эллипсоида уменьшается в константное число раз.
Лемма1. Если система совместна, то в шаре ![E_0 = \| x \| \leqslant \sqrt{n} \Delta([A|b])](/w/images/math/2/5/d/25d44ce397fc0a3af29658c9267b9d23.png) найдется ее решение.
найдется ее решение.
Таким образом получаем, что если система совместна, то эта лемма позволяет локализовать хотбы бы 1 из ее решений
Введем функцию невязки в точке x -- t(x) = maxi((Ax)i − bi). Точка 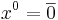 -- это центр шара E0. Если
-- это центр шара E0. Если 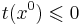 , то x0 -- решение. Если это не так, то возьмем s:
, то x0 -- решение. Если это не так, то возьмем s: 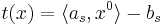 , значит x0 не удовлетворяет s-ому неравенству системы. Всякий вектор x, удовлетворяющий неравенству s, должен лежать в полупространстве
, значит x0 не удовлетворяет s-ому неравенству системы. Всякий вектор x, удовлетворяющий неравенству s, должен лежать в полупространстве 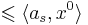 . Пересечение этого полупространства с нашей сферой дают полуэлипсоид. Вокруг получившегося полуэлипсоида описываем новую сферу и повторяем алгоритм заново.
. Пересечение этого полупространства с нашей сферой дают полуэлипсоид. Вокруг получившегося полуэлипсоида описываем новую сферу и повторяем алгоритм заново.
[править] Теория двойственности ЛП
- Методичка, стр. 35-36
- http://www.mathelp.spb.ru/book1/lprog5.htm
Каждой задаче линейного программирования можно определенным образом сопоставить некоторую другую задачу (линейного программирования), называемую двойственной или сопряженной по отношению к исходной или прямой задаче.
Двойственной задачей к задаче линейного программирования на максимум (в форме ОЗЛП можно записать: 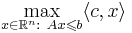 ) называется задача линейного программирования на минимум:
) называется задача линейного программирования на минимум: 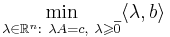
Утверждение Двойственная задача к двойственной задаче совпадает с прямой задачей линейного программирования.
Теорема (двойственности ЛП). Задача ЛП разрешима тогда и только тогда, когда разрешима двойственная к ней. При этом в случае разрешимости оптимальные значения целевых функций совпадают: 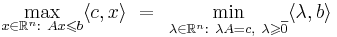
[править] Сведение озЛП к однородной системе уравнений с огрничением x>0
Методичка, стр 36-37
Утверждение. Задача ЛП оптимизации эквивалентна решению системы линейных неравенств.
Утверждение. Задача ЛП оптимизации эквивалентна решению системы линейных уравнений в неотрицательных переменных.
Утверждение. Задача ЛП эквивалентна поиску неотрицательного ненулевого решения однородной системы линейных уравнений.
[править] Идея метода Кармаркара
- Методичка, стр 37-38
- http://logic.pdmi.ras.ru/~yura/modern/02seminar.pdf
Метод Кармаркара.
- На основании предыдущего утверждения (см. вопрос о сведении озЛП к однородной системе), есть возможность свести задачу ЛП к поиску решения СЛАУ
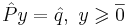 , которая, в свою очередь, сводится к однородной СЛАУ:
, которая, в свою очередь, сводится к однородной СЛАУ: 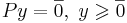
- Введем функцию Кармаркара:
![k(x) = \frac{\left[ (\langle p_1, x \rangle)^2 + \dots + (\langle p_K, x \rangle)^2\right]^{N/2}}{x_1 \cdot x_2 \cdot \dots \cdot x_N}](/w/images/math/d/2/a/d2a0123f059db49edd12e3c433da99a0.png) , где
, где
- N -- число столбцов в P
- K -- число строк в P
-
![p_i, ~ i \in [1,K]](/w/images/math/7/c/3/7c34a57cf32e76b597d04a54ca04b9c2.png) -- строки матрицы P
-- строки матрицы P
- применяя теорему о мере несовместимости и алгоритм округления можно показать, что для решения достаточно найти такой
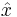 , для которого
, для которого 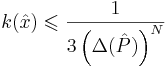
- при этом можно так же показать полиномиальный алгоритм поиска данного приближения, который в курсе не рассматривается.
[править] Следствия систем линейных неравенств. Афинная лемма Фаркаша (без доказательства)
- Методичка, стр. 34-35
- http://imcs.dvgu.ru/lib/nurmi/finmath/node41.html
Система линейных неравенств называется разрешимой, если 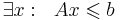
Линейное неравенство 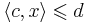 является следствием разрешимой системы ЛН , если для всех x, для которых выполняется сама система, выполняется и следствие:
является следствием разрешимой системы ЛН , если для всех x, для которых выполняется сама система, выполняется и следствие: 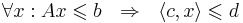
Афинная лемма Фаракша.
Линейное неравентсво является следствием разрешимой в вещественный переменных ЛН , тогда и только тогда, когда существуют 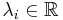 :
:
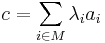
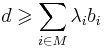
[править] Лемма Фаркаша о неразрешимости
Методичка, стр. 35
Лемма.
Система линейных неравенств неразрешима тогда и только тогда, когда разрешима система:
-
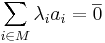 (нулевой вектор)
(нулевой вектор)
-
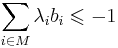
-
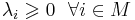
[править] Элементы математического программирования
[править] Классификация задач математического программирования. Преимущества выпуклого случая
Методичка. стр 39-41
Задача математического программирования (ЗМП) -- по заданной f(x) найти 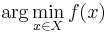 , то есть:
, то есть:
- найти
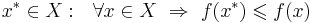 -- решение
-- решение
- f * = f(x * ) -- (оптимальное) значение целевой функции f(x)
- где X -- допустимое множество (множество ограничений)
Классификация проводится по типу допустимого множества X:
- дискретные (комбинаторные) -- множество X конечно или счётно
- целочисленные --

- булевы --

- непрерывные --

- бесконечномерные
- функциональные
Задачи оптимизации бывают:
- условные --
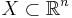
- безусловные --
Классификация по свойствам целевой функции: выпуклость, гладкость и т.п.
Классификация по результату:
- локальная оптимизация
- глобальная оптимизация
Выпуклое множество (вики) -- такое множество, которое содержит вместе с любыми двумя своими точками еще и отрезок, их соединяющий.
Функция f называется выпуклой, если её надграфик (множество точек над графиком: 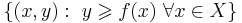 ) является выпуклым множеством.
) является выпуклым множеством.
Утверждение. Любая точка локального минимума выпуклой функции является точкой её глобального минимума.
Преимущества выпуклых задач:
- применим метод эллипсоидов, причем сложность - полиномиальна
- для острых задач (целевая функция убывает в окрестности минимума не медленнее некоторой линейной функции) можно получить точное решение
[править] Формула градиентного метода в задаче безусловной минимизации
Методичка. стр 41-42
Основная идея:
- берем некоторое начальное значение
- итеративно вычисляем градиент целевой функции
- двигаемся в обратном направлении
- и так постепенно приходим к (локальному) минимуму функции
Формула градиентного метода -- xt + 1 = xt − αtgradf(xt), где αt -- шаговый множитель:
- пассивный способ: {αt} выбирается заранее
- адаптивный способ: {αt} выбирается в зависимости от реализующейся xt
- метод скорейшего спуска --
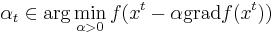
- метод дробления (деления пополам) -- если f(xt + 1) > f(xt), то возвращаемся к шагу t с новым значением αt = αt / 2
- метод скорейшего спуска --
[править] Идея метода Ньютона
Методичка, стр. 43
Метод ньютона -- это фактически градиентный спуск с адаптивыным коэффициентом, который берется, как 2 производная целевой функции.
Реально можно вывести формулу Ньютона из разложения по Тейлору до 2 производной в окрестности точки минимума.
[править] Формула метода Ньютона в задаче безусловной минимизации
Методичка. стр 43
Формула Ньютона -- 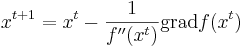 , при этом начальное приближение должно находиться достаточно близко к искомой точке минимума.
, при этом начальное приближение должно находиться достаточно близко к искомой точке минимума.
Метод ньютона имеет квадратичную скорость сходимости: 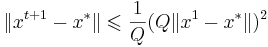 , где Q - некоторая константа
, где Q - некоторая константа
Ограничения:
- невырожденность матрицы 2 производных (гессиана)
- близость начального приближения к точке минимума (
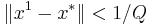 )
)
[править] Идея метода штрафов
Методичка. стр 44
Смысл метода в том, чтобы свести задачу условной оптимизации к задаче безусловной оптимизации, то есть избавится от ограничения на область, в которой ищем минимум.
Для этого вводится так называемая функция штрафа, которая равна нулю в той области, в которой мы "условно оптимизируем" целевую функцию, а в остальных точках добавляет к значению целевой функции некоторое значение (собственно, штраф).
Пример. Пусть область задаётся следующим образом: 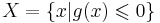 , где g(x) -- некоторая функция. Тогда рассмотрим задачу безусловной минимизации целевой функции f(x) со штрафом:
, где g(x) -- некоторая функция. Тогда рассмотрим задачу безусловной минимизации целевой функции f(x) со штрафом: 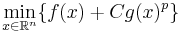 , где C -- некоторая константа [??], а
, где C -- некоторая константа [??], а 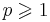 -- параметр штрафа
-- параметр штрафа
[править] Способы решения переборных задач
[править] Методы глобальной минимизации
Методичка. стр. 52 (52-55)
[править] Метод ветвей и границ для глобальной минимизации Липшицевых функций
Методичка. стр. 54
[править] Метод ветвей и границ для ЦЛП. Различные стратегии метода
Методичка. стр. 57
[править] Идея метода ветвей и границ. Пример для задачи БЛП
Методичка. стр. 59
[править] Теорема оптимальности для разложимых функций
Методичка. стр 60
Опр. Функция f называется разделяемой на f1 и f2, если она представима в виде f(x,y) = f1(x,f2(y)).
Опр. Функция f называется разложимой на f1 и f2, если:
- она разделяема на f1 и f2
- f1 монотонно не убывает по последнему аргументу
Теорема оптимальности для разложимых функций: minx,y(f(x,y)) = minx(f1(x,miny(f2(y)))).
Указанная теорема используется для уменьшения размерности оптимизационных задач и в методе ДП.
[править] Применение метода динамического программирования для понижения размерности разложимой оптимизационной задачи
Методичка. стр. 62
[править] Метод динамического программирования для БЛП с неотрицательными коэффициентами
Методичка. стр. 63-64
[править] Неотсортировано
- Полиномиальный алгоритм округления ε1-приближенного решения системы линейных неравенств
- Понятие о временной сложности алгоритмов
- Понятие о недетерминированно-полиномиальных задачах
- Оценка сложности метода эллипсоидов ε2-приближенного решения озЛП


